流控设计背景
阿里云redis服务的一款云产品,它是一个全内存的NoSql数据库,除了内存、CPU资源管理外,流量控制也是保证服务稳定性的重要一环。Redis服务的数据流节点包括proxy节点和存储节点,所有实例的数据访问都要先经过proxy,然后转发到后端对应的redis进程。后端每个存储节点上最多可以部署几百个redis进程,而这些进程一般都属于完全不同用户实例。 我们的服务是以实例为单位来管理用户数据的,内存容量是最核心的资源,实例按存储容量从低到高划分为10种规格,每种存储规格都包括qps、 进/出流量、连接数资源在内的最大使用限制,例如: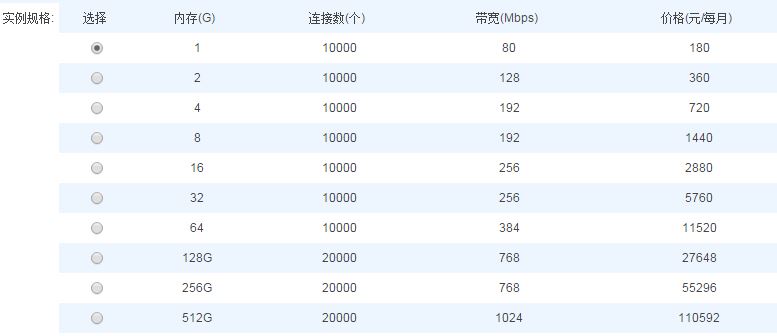
流量控制架构
我们知道redis本身是没有流量控制的,为此我们服务专门增加了一个proxy层来对数据流做控制,客户端的所有请求都要先经过proxy鉴权,鉴权通过才转发给后端对应的redis进程,最后再由proxy将结果回复给客户端,如下图。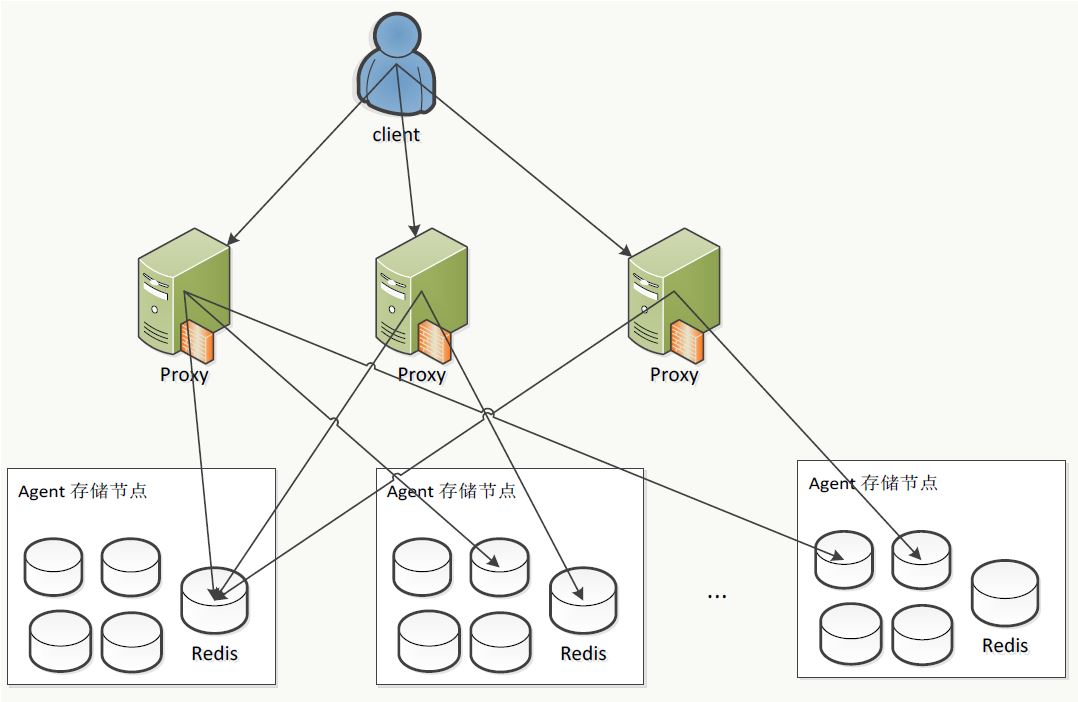
流量控制思路
说到流控,最常见的做法是当流量超出后,proxy 以一定概率随机(跟超出程度相关)对某些请求不做处理直接返回某种错误,例如OCS 对实例就流控就是随机返回BUSY 错误。但是redis 的协议中并没有专门定义类似流量、qps 过大的控制错误码,考虑到外部用户会使用不同客户端,为避免兼容性问题,自定义错误码的做法也不妥。
我们的方案是在每个实例的连接上直接进行网络流量控制,正常情况下,只要客户端过来的tcp 连接上有读事件,proxy 会立马从连接上读出数据并处理请求;但是一旦发现实例流量超出时,会将对应的tcp 连接句柄的读事件从epoll 上注销一段时间,于是tcp 接受缓冲区的数据开始堆积,接收窗口变小,进而达到控制客户端的发送速度、甚至阻塞客户端请求的目的。连接句柄的读事件注销与重新注册使用一个定时器即可,当然定时器的粒度需要非常小,才能控制平滑。
流量统计集中汇总
通过上面的图可知,每个访问我们服务 的实例的请求都必须要经过某一个proxy(由lvs 路由),所以proxy 是能准确记录所有实例实时的访问流量的,但由于proxy 之间是无状态的,相互之间没有感知,而同一个实例可以同时使用1 个到多个proxy。每个proxy 单独做流控明显不合理,所以我们还需要一个全局的统计服务collector 来对各个proxy 上的流量进行实时合并汇总,再把流控的目标结果返回给各个proxy。
流控具体办法
怎么把各个实例总的目标流量合理地分摊给各个proxy以及proxy上的具体连接?
我们遵循“谁放行谁治理,多放行多治理”的原则,如果整个实例上的总流量告警,则所有有该实例流量的proxy都需要进行流控,上面承载的流量越大,流控的力度也越大; 具体来说就是collector上会实时计算出实例当前流量超过配额的比例P,为了将流量控制在配额以内,于是把该实例在每个proxy当前流量除以超额比例P作为期望的目标流量,每个proxy就依据这个值又再计算出每个连接上的目标流量,最后计算出需要休眠各个连接上读事件的时间。怎么保证collector每次合并时既能不遗漏任何proxy上的流量,又能尽量保证数据的实时性?
每个proxy自启动开始,都会定时向collector汇报上面所有活跃实例的流量,汇报间隔必须是固定统一的,这样collector上只要也周期性地合并最近的流量每次就能恰好合并所有proxy。 但是我们后来发现如果collector合并的周期完全与proxy汇报相等的话,偶尔还是会出现缺失proxy的问题,原因是collector和proxy没法做到周期完全精确,每隔一段时间就会出现临界点合并时处恰好错过或再次汇报的情况,所以我们把汇报时间间隔适当改小来解决(小于合并时间间隔)。 当然,还有一种方法保证不遗漏,就是每次collector主动去proxy上主动拉实时流量。流控很容易让用户的访问速率反复波动,出现“用户流量超了->被流控->用户流量降低->不再流控->用户流量又反弹”的循环,如何避免?
出现这种情况的根本原因在于存在非黑即白的流量配额临界点,如果中间开设一个中间缓冲区,就能避免这个问题。 collector因此增加了一个流量缓冲因子traffic_factor(大于1),当发现实例流量超过配额quota_traffic时,即启动流量控制,但是控制的目标流量不是配额本身,而是放大到quota_traffic traffic_factor,这样就算proxy开始启动流控也只是保护性控制:在流量即将越界前就提前启动限制,只要不超过quota_traffic traffic_factor用户就访问速度就不会真正受限。入口、出口是否需要单独做流控?特别是如果是后端有多个redis节点的集群实例?
如果是以读为主的应用(或者某段时间读比较多),出口流量往往明显高于入口流量,这时需要限制实例的出口流量; 反之,如果是以写为主的应用(或者某段时间写比较多),入口流量又会比出口高,这时又需要限制实例的入口流量; 如果读写都很多,则入口出口都需要控制。 所以服务 需要同时对入口和出口进行配额控制,collector上要分别统计入口和出口的流量,入口流控靠限制客户端到proxy的tcp连接上的接收缓冲区读速度,出口流控则是限制后端redis到proxy的接收缓冲区读速度。(集群实例后端会有多个分节点,所以proxy上一个前端客户端连接对应的后端多个连接也要分别限流)如何对集群多节点实例访问的热点流控?
如果用户并行开启很多客户端,按照SLB负载均衡逻辑会转发给不同的proxy,如果这些客户端又恰好是同时大量访问落在同一个redis节点的key,会出现整个实例流量未超标(集群实例流量配额一般较高),但是后端的这个redis进程的流量很高,影响该机器上的其他的实例进程。 所以服务 同时又增加了对后端redis节点进程的流控控制,当然因为redis进程不支持流控,还是只能在proxy上限制后端单个redis节点出口流量来做。qps如何限制?
因为redis没有标准协议可以优雅地拒绝单个请求,所以qps是不能直接被限制的,在我们服务里collector会将qps超额程度转化为流量的形式返回给proxy,这样proxy就能跟控制流量一样限制qps了。连接数为什么也要限制?
proxy是给所有实例一起可用的,每个连接需要占用一些内存和一个文件描述符,而且proxy到redis的后端连接在不同实例之间是不共享的(因为要支持select、pub、sub等命令很麻烦),所以proxy的连接数其实也是很容易被使用过度的,必须做下约束:如果某个实例的连接数超过配置,则它发到proxy的所有新连接都会被拒绝掉。
待解决的问题
目前压测发现的流控还不能完全符合预期,主要有三个因素:
- 流控的滞后性,导致用户流量会出现短时非常高的现象。
- 多层分摊后的精度损失。
因为最终限流的基本单位是一个tcp连接,当经过多层分摊后,每个连接上的流量值太小而误差比被放大。
对如集群多节点实例,如果多客户端同时对同一个后端redis节点大量写入,整体入口没超但是单节点流量负载很高的情况,现在没有想到好的方法,这点其实很容易被攻击点。后续可以考虑在redis上也增加流控功能。 - 流控方式不友好,用户无法判断是否被流控。
这个问题是最突出,但却最难解决的。因为Redis协议本身没有流控相关状态,如果我们自己添加,将会造成与社区不兼容。