热点Key问题
大促期间的另一个常见问题是Key热点问题。部分Key(可能对应用与某个促销商品)集中于同一机器量,使得所有流量涌向同一机器,成为系统的瓶颈。该问题的挑战在于它无法通过增加机器容量来解决。
解决该问题的办法有很多,最有效果的方式是在业务层对热点数据进行切分。但对于有些情况,如小米双11促销,单台小米机型QPS超过百万,业务无法进行切分。
该问题最常见的解决办法是多写策略。如搭建备用集群,写的时候双写或者异步同步,读的时候就相应的能从多个地方读。但上述方案对于双11这种读、写压力都很大的场景,还是略显不足。
还有就是通过牺牲数据一致性来提升访问效率。一种是针对读的客户端缓存,另一种是针对写的由Facebook Memcached论文中提出Lease租约策略。
客户端缓存的思想是将部分热点内存缓存在客户端,而避免每次访问都去访问服务器。其缺点是本地缓存可能不是最新的。
Lease租约策略则要求每次写key时,都需要事先获得该Key的Token。这能有两个用途,一方面是避免写后读问题,详细可以看这里。另一方面服务器可以通过控制连接在每秒获取Key的频率达到限流的作用,避免写入过多,造成惊群效应。
设计
通过对我们承接的业务进行分析,在促销期间应用对于数据一致性的需求要远低于可用性的需求,他们能容忍数据在短时间内不准确。依据该原则,我们选择客户端缓存办法。
客户端缓存方案包含两个部分,服务端热点统计和客户端本地缓存。
服务端热点统计是用于探测服务当前热点,客户端缓存是将服务端的热点数据存于本地,待下次访问时直接返回。
服务端热点统计
服务端热点Key统计的办法有很多,最常见的办法是直接抽样N次请求取出Topk让客户端进行缓存,但该方法存在一个很大的问题:Topk的准确性,依赖于抽样的次数。较少的抽样次数,可能导致热点key不准确,且频繁发生变化。而较多的抽样,可能提升热点key探测花费的时间、导致热点已过,同时还提高了内存占用。
我们需要一个自适应的抽样办法,能在热点出现时及时发现。这里我们提出了一种双层抽样办法。它分为采样阶段和定位阶段来探测热点key,最后定时反馈热点key给客户端。其具体流程如下。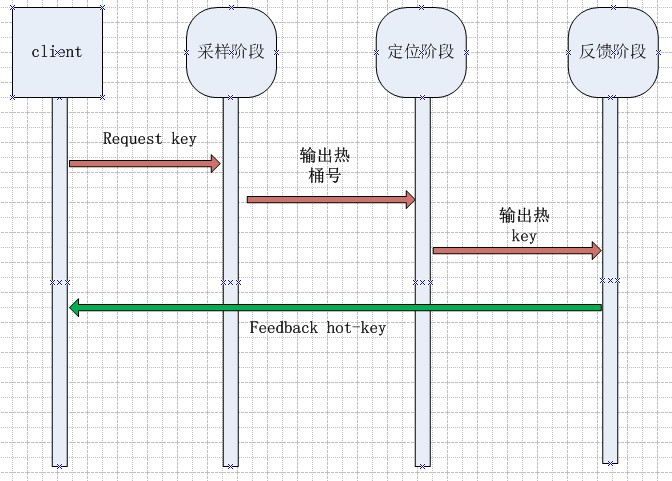
采样阶段
我们首先将数据空间划分成1024个桶,记录每个桶的命中次数。为了提升性能,每次采样,各个线程都是采用try_lock的方式获取锁,只有拿到锁的线程才会进行统计,否则直接放行。
我们采样一个较小的样本N,通过采样桶的标准差(反映了数据的离散程度)来确定是否存在热点。其具体的判断标准为,当标准差大于整体均值的K倍时,我们认为存在热点。此时选取命中次数最多的桶作为候选桶,进入定位阶段。1
if Deviation > Avg(Count) * K:
Candidate = MAX{Count i}
定位阶段
当定位到热桶后,我们对该桶里命中的Key继续进行采样,采样M次(M < N)。当采样完成后,将选出大于T次的key作为热点key,放入服务器的热点Key LRUCache中,清0进行下一次定位。
在程序的运行过程中,采样阶段和定位阶段是同时进行的,当采样N次结束后,发现热点Key发生了变化,将会使得定位阶段重新开始。
线上运行效果
在实际过程中,我们选取N=10000,M=1000,K=1.5,T=100。
两次采样的方法,大幅减少了抽样次数,当出现热点时,我们通常能在2*N次采样即可确定热点,占用的内存资源也较少。最后对于我们的系统,热点key的探测还要结合迁移功能。当检测到某个热点key时,在使用客户端缓存的同时,我们可能还希望能将该热点迁移到其它机器。上述热点key的办法,能有效帮助我们定位到一个热点桶,当发现桶热点持续时,我们可以发出迁移指令,迁移或者复制热点数据到其它机器。
客户端的热点key缓存
开启了热点key缓存的客户端将定时向服务器咨询热点的key列表,并缓存在本地的缓存中。对于每次读请求,将首先检查key是否存在于本地缓存中,如果存在则直接返回。其具体流程如下:
为了更好的理解这个过程,有一下几个要点需要注意:
1.本地缓存与服务器间如何同步
每次写操作强制删除本地cache的key,读操作时,更新后端服务器的值到本地cache。2.本地缓存数据淘汰策略
本地缓存包含两种淘汰策略,分别是根据数据量大小的逐出的策略和根据时间的过期淘汰策略。- 容量逐出策略:它是为了限制本地缓存占用的内存大小。当缓存内存超过该阈值时,会采用LRU策略逐出。在实际运行中,客户端设置的本地容量通常较小,默认只能存30个key,服务端稍大一些为100个。LRU的实现我们用的是google的ConcurrentLinkedHashMap,它对于多线程更新时相比LinkedHashMap性能更好,读写性能提升20%。它更新LRU链表是异步的,且合并了多次读操作需要的更新。
过期淘汰策略:它是为了限制服务器与客户端之间的数据不一致的窗口。当客户端向服务端读热点key操作成功后,在添加入本地缓存表的同时,会设置一个在过期时间(默认30ms)。一旦过期,客户端将需要重新从服务端获取该key值。
3.防止击穿
应用使用客户端访问我们服务时时,大多是多线程访问。试想当多个线程发现某个key的存活超过过期时间时,会做什么处理呢?会有大量请求击穿本地缓存,同时访问后端服务器,如下图。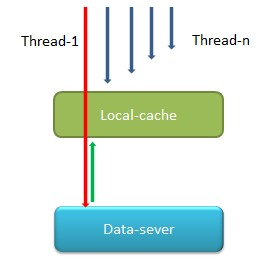
为了解决这样的击穿问题,这里加了一个过期时间续期的操作。当多个线程并发读取某个key1时,第一个竞争到锁的线程会判断key的过期时间,如果已经过期,则返回null,并对该key续期(即延长过期时间),由于返回的是null,该线程会击穿Localcache继续向server发起请求,并更新本地Localcache。其他线程访问key时,已经是续期之后,这些线程的访问该key时,就不会发现已经过期,读到的是老的value,等到第一个线程完成server端key-value到Localcache的更新结束后,所有线程都将读到新value。这样的好处是不会在某个key过期时间一到就击穿Localcache,并大量的访问server,对server造成压力。
如图,只有thread-1会击穿Localcache,其他线程拿到的要么是老的value,要么是最新value。4.拷贝机制
当客户端需要将获取的热点key对应的value写入到本地缓存时,很多场景需要深拷贝,以防止同一个对象在本地缓存之外被修改,从而造成本地缓存中的value与后端server的value不一致。
但是深拷贝操作本身很耗费CPU,如果每次往本地缓存中写value都需要clone的话,非常影响性能。并且我们观察发现,大部分用户在一段时间内访问一个key的机会只有一次,比如获取一个商品的所有规格信息,将需要一个for迭代循环,每次访问不同(key + i),就需要把每个key对应的value,拷贝一次再写入本地缓存中。
为了提升拷贝效率,我们在第一次读取到热点key的值时,只把null当做值写入缓存。只有当本地缓存中该key还有第二次机会被访问时,客户端拿到null就会重新去服务器读最新数据,这时我们才真实的将读到的value并深拷贝到本地缓存中。因为我们认为该key有第二次读到就会有更多次机会被读到。