在海量数据,高并发时代的今天,单机由于其CPU,磁盘IO,网络带宽以及存储空间等原因,已经不再能及时响应用户的所有请求,系统都开始走向分布式,由多台机器组件成一个集群响应用户请求。具体到分布式存储系统,一个很重要的问题就在于数据的同步。本文将简要介绍当前较为流行的数据同步方案,简要分析其原理和利弊,希望能起到一个抛砖引玉的作用。
数据同步初步
数据同步的基本思想很简单,就是将单台机器上的用户数据和请求,通过复制Replicate的方式复制用户的操作命令到多台机器执行。从而应对当某台机器出现故障时,数据仍能存其他机器获取。
一种最朴素的实现方式是采用多台机器构成集群存储数据,机器按照职责分为一个主节点和多个从节点。其中主节点负责接收用户的数据请求,在本地执行用户请求的同时,将数据复制到集群中其他从节点。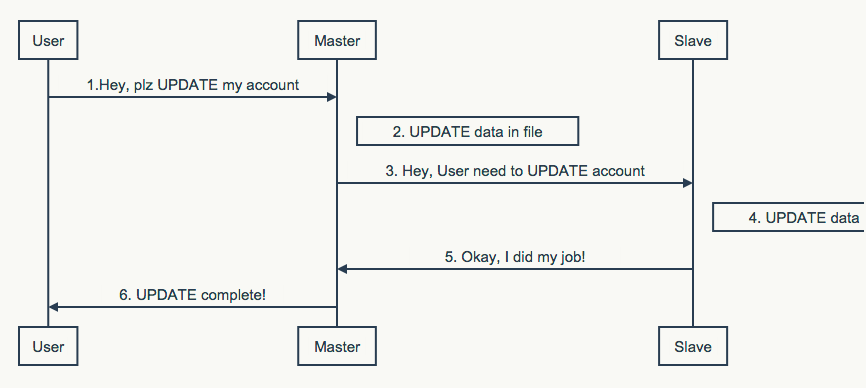
上图中描述了同步复制的基本流程。
主节点收到用户请求后,在本地执行的同时,将请求转发到了从节点。当主节点和从节点都执行完毕后,像用户发出响应。此方法保证了主节点和从节点的数据是一致的,从而当节点出现故障时,从节点可以取而代之,而不会造成数据的损失。为了提供更高的数据可靠性,可采用1主多从的方式。
此方案被称作”全同步方案”,能提供良好的可靠性,以及数据读取性能(每个节点都能读)。同时通过调整步骤3,4,5,6的顺序,以及最大允许的主从之间的数据差额,可产生许多变形,诸如全异步方案,半异步方案等。许多熟知系统(如Mysql,Redis)提供的就是以上方案。原则上,主/从数据差额越大,性能越高,但同时数据丢失的风险越高。
此系统的最大问题在于,当系统需要保证数据一致时,写入性能取决于集群中所有节点中最慢的那个。对于将部分节点失效视为系统正常行为的分布式系统,往往是不可接受的。
为了解决该问题,大致分为三类解决方案:在全同步方案进行改进的半同步方案,利用同步协议的类Paxos方案,以及牺牲数据一致性的最终一致性方案。
半同步方案
半同步方案虽然存在多种变形,但基本思想都是结合同步方案和异步方案,使得系统在尽可能保证数据可靠性的前提下,提升系统的性能。该方案仍然采用主从架构,只是对数据同步过程进行了部分闲置。这里简要介绍Kafka采用的半同步方案。
Kafka采用的也是一主多从模式,其中只有主负责接收用户的读写请求,从节点只负责被动的接受主节点的数据。但它对主从同步进行了如下的限制:
- 从节点需定时汇报自身的同步状态到中央节点。当从节点的数据与主节点的数据差异在指定条数M以内时,被认为是同步状态(in-sync),否则认为是追赶状态(in-pace)。
- 只有处于同步状态的节点,当主节点出现故障时,才能被选为新的节点。当系统中没有处于同步状态的节点时,系统可选择停止工作,或者发出数据丢失警告后继续工作。
半同步系统总结
半同步系统方案实现较为简单,用户可通过设置数据差异数目M,调节系统对于数据一致性和性能的要求。它防止了集群中某些节点的故障而影响全局,提升了系统的系统,但妥协了系统的可靠性,其在任意时刻其最大容忍的节点故障数目等于处于同步状态的节点数目。
类Paxos方案
Paxos是一个经典的用于保证集群数据强一致性的算法,它的基本思想是利用2N+1个节点组成系统集群,通过同步协议保证当系统中不大于N个节点失去响应后,系统仍能正常工作,并能保证用户请求的时序(将在后文介绍)。它的每次写操作只要求N+1个以上处于”同步”状态中的节点确认,即可返回成功。
此算法描述较为复杂,在实现过程中存在着多种变种,较为经典的包括Zookeeper使用的Zab算法,Raft算法等等。如果想知道更详细的算法描述,可参考之前博文Raft:都能理解的强数据一致性算法。
Paxos在保证了系统的可靠性同时,避免了系统因为少数节点处于异常状态,而影响系统性能问题,写入性能取决于2N+1个节点中处于”同步”状态节点的最快的N个。
类Paxos方案总结
但此方案妥协了资源和性能。同样提供N个节点的宕机保证,相比全同步和半同步方案多需要额外的N-1台机器。主节点的网络开销也提高了一倍,需要多复制额更多的数据。同时因为同步协议,节点之间的信息交互也相比此前的同步方案和半同步方案更多,进一步影响了系统的响应速度。最后其实现的复杂度,也使得许多开放者望而却步。
最终一致性系统
对于许多系统,它们对于性能有很高的要求,而不希望使用的”昂贵”的同步协议(如Paxos)去保证用户请求的时序以及集群数据的一致性。同时它们可能认为”可用”比”可靠”重要,当集群出现故障时,宁可选择返回部分错误的数据,而不愿意使系统出现宕机。此前的三种强一致性方案都有明确的主节点概念(小部分Paxos方案可能不是),由它负责接收所有用户请求,并复制到其它节点。当主节点失败后,为了确保集群数据的一致性,需要经历重新选主的过程后才能重新接收用户请求,上述系统提供的是CP,同时它们保留了用户请求的时序。
弱一致性系统通常也被称作最终一致性系统,它最大限度保证系统可用,接受数据在集群中各个节点中存在短期的不一致,而只需保证数据最终是统一的即可,选择是AP。为了保证系统的可用性(任何节点失效系统都能正常工作),它们通常弱化了主节点的概念,集群中节点是对等的(没有主从之分),都能接收读写请求,谁接收到用户写请求,谁负责数据日志的复制。一些系统甚至支持多个节点的同时写入。但不论对于单点写入还是多点写入,系统都将面临由数据请求的时序的错乱造成的数据正确性问题。
多主的困境:请求的时序
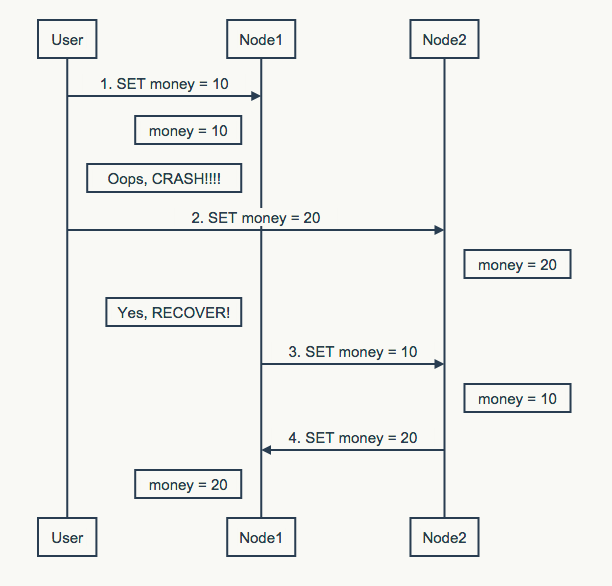
上图是单点写入系统的例子,对于多点写入系统问题更甚。用户向节点1发送了第一条数据后,节点1突然宕机。系统此时仍然正常运作,用户向节点2发送了第二条数据。接着节点1恢复了,复制第一条数据到节点2。节点2紧接着也将请求复制到了节点1。最终节点1的数据成了20,节点2的数据是10,节点数据将不统一!同时需要注意的是此结果是不可预期的,4和3的顺序换一下,结果将又会不一样。
上述问题的根源在于,系统中允许多个节点写入。多个节点写入,将可能颠倒用户的原有请求序列,使得系统中同步后得到的请求序列是难于预测的。但往往系统的运行结果却又依赖于节点收到请求的时序,如本例子中节点1先收到了消息1和2,而节点2却是相反的,造成了两个节点数据的不一致。但由于最终一致性系统需要保证0宕机时间,选择多主是必然结果。
我们称以上数据请求序列不一致问题为请求的冲突,系统,它企图将颠倒的用户请求序列复原到原有请求序列。但事实上对于许多场景,完美的复原是不可能的,这造成了数据的不一致。这个缺点很大程度限制了最终一致性系统的应用场景,使得系统需要限制提供的数据结构和数据接口,并专为某类特殊的应用场景进行设计,缺乏通用性。
冲突的合并算法
由上文可知,乱序请求的合并是最终一致性需要解决的最棘手问题。在解决它时,系统通常分为两步,首先对多个请求进行一一标示,并在之后对多个标示的数据请求进行合并。
数据的版本标识
请求的标识一般选用时间戳的方案,对每个请求标记一个时间戳,并记录收到它它通常分为两种。
服务端的全局时间戳
服务器集群依赖于全局的时间服务器,确保每个服务器的时间都是一致的。
在实现时,每条数据记录由三元组(Key,Value,Timestamp)组成,其中Timestamp标志请求时间。
此种方案易于实现,当集群规模较大和多地部署时,时间可能存在不精确的问题。服务端的逻辑时间戳:向量时间(Vector Clock)
放弃统一时间服务器,而采用服务器自身的逻辑时间。其同样采用三元组,但区别在于逻辑时间进一步由两部分组成(NodeId, KeyId)。其中NodeId用来标示服务器,KeyId用来标示记录,这里只需保证后来的请求Id大于之前的Id即可。KeyId可采用本地时间戳,为了保证机器出现故障后时间没出现问题,可存定期存储当前时间戳。当下次启动时,与启动时时间进行比较,如启动时间较早,报错误,停止启动即可。
多版本数据合并
多版本数据合并时用于合并系统中存在的多个数据版本,使各个节点对该条数据达成共识。它算法通常也分为两种方法:
- 最后写入成功。LWW(Last Write Win)
当系统中对数据存在多个版本时,选择最大的时间戳作为最后的结果。
对应于此前例子,使用此算法时,节点2在收到节点1传来的请求后,将发现其自身数据时间戳较新,将放弃此次请求。而节点1将执行更新。从而保证两个节点的值都为20。
此方案的代表系统是Cassandra和Riak,其优点在于合并开销低,系统在执行合并时不需要知道数据的具体内容,即可执行合并。
- 自定义合并算法
当系统中数据存在多个版本时,将执行用户提供的合并算法对数据进行合并。
此方案的代表系统是Dynamo,它选择合并算法是由用户来定义。
最后写入成功,使得数据在合并时最终只能选择最后一次用户修改。但对于许多场景,我们希望能最终执行所有的修改请求。考虑Amazon电商用户购物车: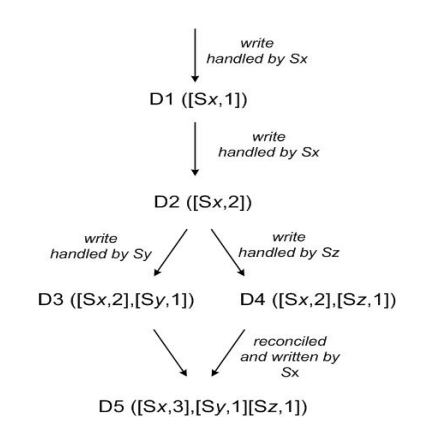
D1,D2, D3,D4操作都是添加商品到购物车。其中D1,D2操作同步到了集群所有节点。但D3,D4分别发送给了y服务器和z服务器,使系统中出现了两个不同版本。此后当两者数据执行同步时,如果采用时间戳的办法,则意味着选择D3,D4中的一个,导致用户购物车中丢失一个商品。但如果用户给定的同步算法,首先比较两者数据上的差异,再把不同的数据进行合并,此时系统将不存在请求丢失的风险。
此方法看似美好其实不然,它存在两个问题:
- 执行数据合并带来了性能损失。它要求系统在合并时读取出各个版本的数据值,同时对于涉及数据的压缩的系统,还包括解码和编码的过程。其流程将会是:节点收到数据请求,读取原有数据并进行解码,执行合并算法,最后编码Encode数据写入到数据节点。
- 有时很难甚至不可能编写出能应对所有场景的合并函数
可靠性:最少读取和写入(Quorum Read and Write)
为了提升系统的可靠性以及减少数据冲突的,最终一致性系统通常对完成读写操作的最少节点数目进行限制,但它不像类Paxos算法要求至少一半以上写成功,而可由用户进行灵活的配置。这里我们设N为集群节点数目,W为最少写入要求,R为最少读取要求。
最少写入(Quorum Write)
用户的每个写入请求最少需要在至少W个节点写入成功,系统才能返回最少读取(Quorum Read)
用户的每个读取请求最少需要从至少R个节点读取成功后,才算读取完成。最后用户将在读取到的R个结果中执行响应的合并算法,得到”正确”的值。
W和R设置的越高,系统对应的读写速度就越慢,因为此时系统性能取决于W和R中最慢的那个节点。但另一方面,此时用户读到最新数据的概率越高,同个数据产生多个版本的概率较少,数据的安全性也越高。对于Dynamo和Riak,默认配置当N=3时,W=2, R=2。
对于Cassandra,默认配置N=3时,W=1, R=1。
值得注意的是,当W+R > N时,此时系统能保证只要W < N,系统都将无法保证请求时序,从而可能违背数据的一致性。
复制收敛的数据类型(Convergent replicated data types)
最后简单介绍最终一致性系统中常提供的数据类型CRDT。
经过此前数据合并的问题,我们可能会对哪些请求序列可以被恢复而哪些请求不可以产生兴趣。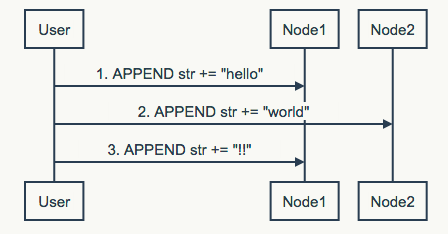
如上图字符串末尾添加Apppend操作,无论采用LWW还是自定义算法,都无法有效的将请求进行还原。
但对于另外一些操作,如此前描述的SET操作,则能通过LWW进行恢复。
人们经过总结,能完整进行恢复的数据类型和操作进行了归类,将他们称作复制收敛类型。数据收敛操作需满足下面三个条件:
- 交换律:a+b = b + a 操作顺序不影响结果
- 结合律:(a+b)+c = a+(b+c) 操作结合影响结果
- 幂等: a+a = a,序列执行多次结果仍是一致的
诸如MAX,MIN、删除、清0等操作就符合要求。
数据收敛类型是指提供数据收敛操作的数据类型,以下为收敛数据类型的例子,更多可查看论文survey paper from Shapiro et al
- Counter
每个Counter对应一个Set集合,每次加数或者减数操作,对应集合中插一个正数或者负数(这里需要随机生成一个Key,并保证唯一),最后Counter的结果为Sum(Counter)。- LWW Set
使用两个集合Set,分别负责SET操作和REMOVE操作,均将其对应于集合SET操作。集合的结果将根据LWW规则合并两个集合。
最终一致性系统总结
最终一致性方案相较此前的强一致性方案,对业务场景提出了更高的要求。它不能保证用户读到的数据是最新的,甚至不保证用户要求的结果是正确的。但它提供了”0宕机”的服务承诺,可调节的系统性能,实现也相较Paxos更为简单。
扩展阅读
- The network is reliable
- Strong Consitency Model
- Dynamo: All things distrubuted
- Basho: Why vector clocks are easy
- Basho: Why vector clocks are easy
- Datastax: Why Cassandra don’t need vector clocks
- Distributed System for fun and profit: Chapter 4: Replication
- Distributed System for fun and profit: Chapter 5: Eventual Consistency