每年一度的双11已经过完,相比往年不同今年有幸参加了双11全过程。我所在的缓存团队承担着双11很重要的职责,负责存储商品库存、全站用户Session、购物车等峰值QPS上千万级别的大业务。值得骄傲的是,团队的服务除了在0点时极短时间内对购物车和无线业务实施了限流,整个过程异常稳定。
关于如何架构亿万级别QPS系统或者秒杀系统,之前在网络上已经讨论的很多,主要涉及负载均衡、CDN、缓存、静态化、降级、限流、数据压缩等。但那些讨论往往面太广,趁着现在双11余韵还在,本篇文章将站在我们的键值存储服务Tair系统的角度来阐述,我们是如何应对双11的。
流量突增问题
大促最明显的现象是在短时间内有海量并发,造成服务器过载,资源使用率急剧提升,服务响应变慢,甚至有宕机风险。
解决办法分大致分为两类,提前预防,案发时应急处理。
提前预防是在大促发生之前做的准备工作。它依赖于客户在事先对其使用资源的评估,一次好的预估往往比临时的应急处理方案要更有用的多。通常在大促发生之前,我们通过多次对促销时流量的模拟,反复调整机器的数量,最后设置一个合理的值,这里主要考验的是对系统和用户行为的了解。
但通常我们很难保证业务方对于资源的使用有着准确的预估,当超过预期的流量导入到系统的时候,系统需要应急办法来处理。
对于我们缓存系统,应急办法主要涉及两种:
- 集群的扩容
通过增加机器的方式,来均摊负载。该办法思路简单,但在实践过程中,如果直接使用,效果往往很差。因为在机器负载很高的时候,我们执行的扩容操作可能会进一步恶化系统性能。针对我们缓存系统,在大促时命中率往往超过99.99%,贸然的集群扩容,将极有可能击穿后端存储系统。
为了解决这个问题,我们在扩容之后会事先对集群进行预热,只有当命中率达到预期后才执行扩容。
流量控制系统
当远超出预期的请求到达服务时我们需要一种机器资源的保护策略:流量控制。在海量并发请求到来时及时返回错误告知客户端减少请求发送数量,让客户端直接收到返回错误,这样的收益来自两个方面:
- 1.避免服务器过载。如过长请求排队造成的无谓的CPU、内存、网络等性能损失。
- 2.客户端快速收到错误,使其进入错误处理逻辑。(如直接读本地内存或磁盘)
对于我们的缓存系统,该方法极为关键。系统采用的是做租户模型,承接了公司内部超过500个应用,各个应用公用一个集群。如果因为少数应用的并发流量影响整个系统,将造成极大的灾难。其次不同的应用的关键程度不一,我们需要一个更灵活的资源管理办法来实现服务的等级以及关键时候的降级。
支持服务分级的流量控制系统
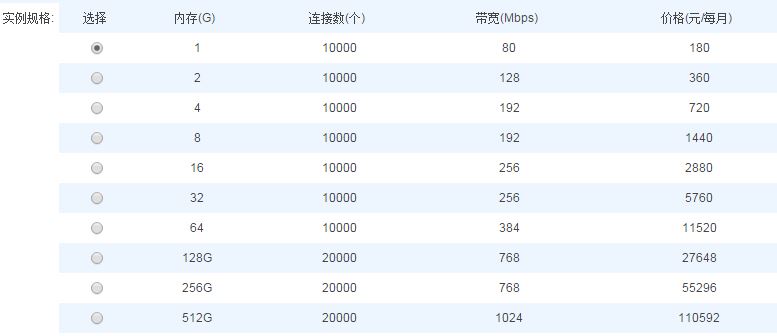
我们提出了基于流量控制的有限服务使用承诺。应用在申请接入我们服务之前,将需要提供其预期的资源使用量。这包括两个值:
- 基本的资源使用量,不管在任何时候,我们的服务都需要提供以上资源(如100w QPS,1w连接,1GB流量)。
- 最大资源使用量(如150W QPS, 2w连接),当客户资源使用量超过该值时,我们将限制其资源使用。
在提供上述全局维度的服务承诺同时,还限制了单机维度的资源使用(如单机5w QPS,1000连接)。
对于单机维度的限流,它的实现较简单,统计实例级别实时的资源的访问后,计算出流控状态,定时推送给客户端即可,这里不做过多阐述,主要介绍实例维度的限流。
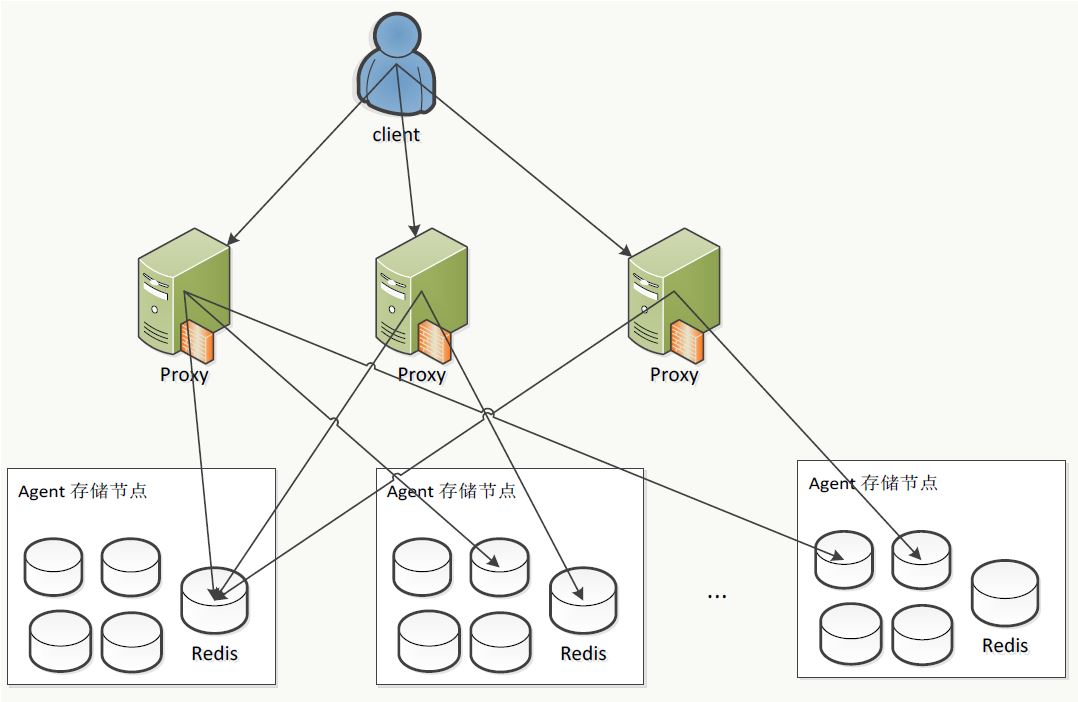
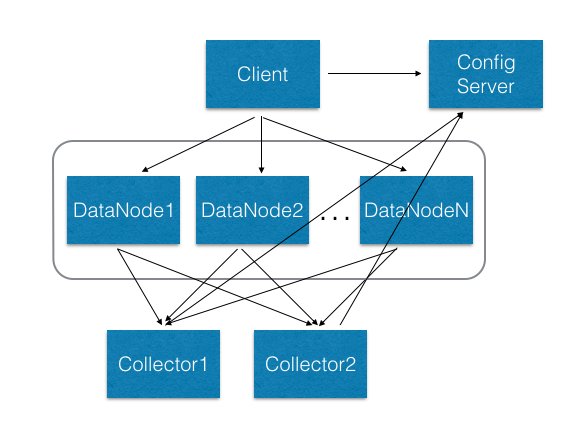
实例维度的限流,是指在集群层面限制单个应用的整体的资源损耗。由于我们缓存服务采用的是多租户模型,应用的数据分散在集群中多个服务器中,其架构如下图。
 。
。
为了统计应用的全局的资源访问信息,数据服务器将各个应用消耗的资源信息统一汇聚到Collector服务器。
Collector汇总后,推送需要限流的实例给数据服务器,接着数据服务器收到后向客户端发出限流命令。
客户端会根据限流命令来以一定概率直接反馈错误,达到限流的效果。
ConfigServer是元数据节点,负责存储提前协商好的资源使用信息,并定时推送该信息给Collector。当临时需要对服务进行降级时,也是通过向ConfigServer发出请求,实现临时限流。
流量控制系统的具体实现
Collector实现
在收集端Collector负责汇总和计算客户端的流控状态。我们将提前会为每个应用设置事先约定的低水位和高水位阈值在Collector数据库中。Collector通过该阈值来控制实例限流的状态。
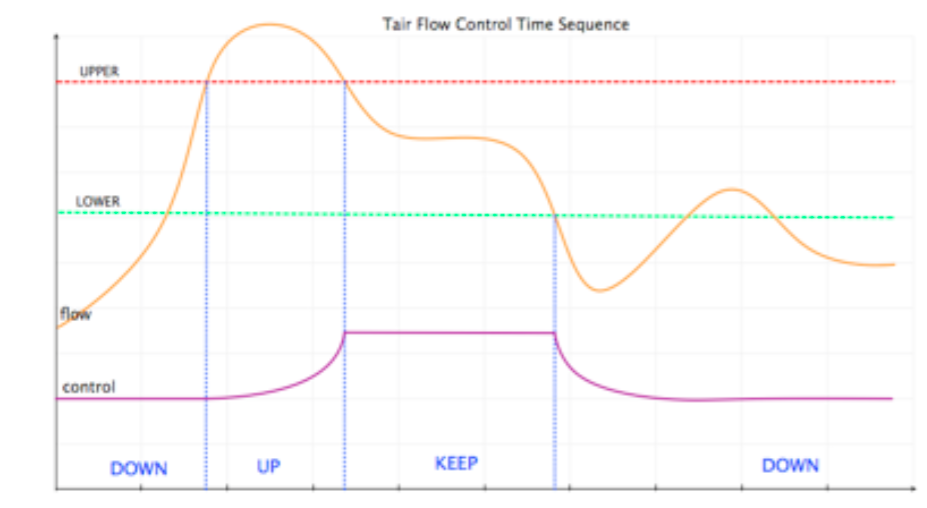
每个实例限流有三种状态:Up, Keep, Down。当超过高水位线开始发出限流指令,并设置状态为Up。当处于低水位线和高水位线之间时,将设置为Keep,低于低水位线时为Down。Collector将定时推送实例的流控状态。
- 高可用
由于Collector在限流系统中处于核心地位,为了保证其高可用,每个集群启用两台彼此不交互的Collector。
每次实例将访问流量推送给两个Collector,它们都会进行计算,并推送限流结果。数据服务器收到任意一个限流结果,都会进行流控。
客户端实现
在客户端,客户会维护一个限流窗口值Threshold,并根据服务器推送的限流状态,来调整该值。其具体的计算方式如下:
初始时该窗口值为0。当收到服务器Up限流命令时,会提高限流值。Keep时,保持该值。Down则降低限流值。其公式为:
1
| Threshold = Threshold + UP_FACTOR*(MAX_THRESHOLD-Threshold)
Threshold = Threshold + DOWN_FACTOR*Threashold
|
计算出该值后,在每次访问时,都会首先random(0, MAX_THRESHOLD)的值,来与当前Threshold值进行比较,如果低于它则直接返回错误。
线上运行效果
在实际运行中我们设置上下因子为0.25,MAX_THRESHOLD为1000。通过服务端和客户端相结合的方式,我们实例资源使用量处于低水位线到高水位线之间的效果,真实数据如下图:
延伸阅读
- 淘宝开源Key/Value结构数据存储系统Tair技术剖析
- 由12306.cn谈谈网站性能技术
- 移动互联网海量访问系统设计